 データ配置の罠
データ配置の罠
データ配置の罠
データ配置の罠
例えば要素数4のchar型(1Byte)の配列
c[4] = {0x10, 0x20, 0x30, 0x40}
を宣言したとしましょう。
そのとき、先頭の要素に割り当てられたメモリのアドレスが0x150だったとすると、配列の要素は以下のような順に配置されます。
これは直感的に当たり前のような気がします。
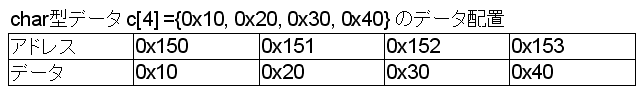
では要素数2のint型(2Byte)の配列
i[2] = {0x1020, 0x3040}
を宣言すると配列の要素はどのように配置されるでしょう。
同じように先頭の要素に割り当てられたメモリのアドレスは0x150とします。
なんとなくこれは上と同じになりそうな気がします。普通に上から並べていけばそうなりますから。
誰だってそう思います。僕もそう思います。
しかし現実は無情。下のようになります。

つまり、2Byte以上のデータはByte毎に逆順となってメモリに配置されます。
これは何を意味するのでしょう。
例えばi[0]の上位Byteすなわち 0x10 を取り出したいとします。
直感的にはなんとなくchar*型でキャストしてしまえば簡単に取り出せそうな気がします。つまり、
char upper = *((char*)i);
です。シフト演算などが入らないのでこの方が効率がよさそうに見えます。しかし実際はデータが逆順に格納されているため、
upper
に入るのは0x20なのです。
このように2Byte以上のデータ型の格納方法が逆順であるかどうかは実はデバイスにより異なります。 PICのように逆順で格納する方式をリトルエンディアンと呼びます。 逆順になっていない方式をビッグエンディアンと呼びます。 どちらを選ぶかはデバイスを作るメーカー各社の趣味によります。
それほど効率を追い求める必要がないなら、ビッグエンディアンかリトルエンディアンかを意識する必要のないプログラムにすべきです。
キャストは使わず、
char upper = i[0] >> 8;
としましょう。こうすればどちらのエンディアンでも問題ありません。ビットシフト演算子はデータ格納方法によらない演算なのです。
ビットシフトを8回するとすると、なんとなく効率が悪そうですが、
実際のところはコンパイラの最適化機能により恐らくキャストと同じようなことが行なわれることになると思います。